Mapping
개발을 하다 보면 DTO같은 모델에 대해 많은 매핑 작업을 하게 되며 어플리케이션의 규모가 커질수록 이 작업은 의외로 성능으로나 생산성으로나 큰 부분을 차지하게 된다.
매핑 작업은 직접 코드를 구현하거나 매핑 프레임워크를 이용해 처리할 수 있는데 직접 코드로 구현하는 방식은 작성 및 관리에 많은 리소스를 소모하기 때문에 보통 매핑 프레임워크를 사용하게 된다.
여기서는 대표적인 매퍼 프레임워크인 MapStruct, ModelMapper의 성능을 비교해 어떤 것을 좋을지 알아본다. 이 외에도 여러 프레임워크가 알려져 있지만 선택 후보에서 제외하게 된 이유도 함께 남긴다.
제외된 후보들
이 글에서는 MapStruct와 ModelMapper만 비교한다. 이 외에도 JMapper, Orika, Dozer 등 알려진 프레임워크들이 있는데 어째서 선택 후보에서 제외하게 되었을까?
2019년 1.5.4버전이 릴리즈된 이후 현재는 관리되지 않는 것으로 보인다.
2021년 4월 6.5.2버전이 릴리즈된 이후 현재 공식적으로 사용하는 것을 권장하지 않고 있다.
2016년 12월 1.6.1버전이 릴리즈된 이후 현재 수익성의 문제로 관리되지 않고 있다.
성능 측정 준비
성능 측정은 Entity를 DTO로 변환하는 매핑 작업을 기준으로 한다. 하나의 인터페이스와 매핑 방식 별로 구현체를 생성한다. 수동 구현 방식을 대조군으로 포함해 비교한다.
1. 매핑 모델 생성
1
2
3
4
5
6
7
8
9
10
11
public class Member {
private String name;
private int age;
private Phone phone;
private Address address;
private List<Order> orders;
private String introduction;
...getter
...setter
}
1
2
3
4
5
6
7
8
9
10
11
public class MemberDto {
private String name;
private int age;
private Phone phone;
private Address address;
private List<OrderDto> orders;
private String introduction;
...getter
...setter
}
2. 매핑 인터페이스 생성
1
2
3
4
5
public interface BaseMapper<E, D> {
D map(E e);
List<D> map(List<E> e);
}
1
2
3
4
5
6
7
8
9
10
11
public interface MemberMapper extends BaseMapper<Member, MemberDto> {
@Override
default List<MemberDto> map(List<Member> members) {
List<MemberDto> result = new ArrayList<>(members.size());
for (Member member : members) {
result.add(map(member));
}
return result;
}
}
3. 수동 매핑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class ManuallyMapper implements MemberMapper {
@Override
public MemberDto map(Member member) {
List<OrderDto> orders = new ArrayList<>(member.getOrders().size());
for (Order order : member.getOrders()) {
orders.add(OrderDto.from(order));
}
MemberDto dto = new MemberDto();
dto.setAddress(member.getAddress());
dto.setAge(member.getAge());
dto.setIntroduction(member.getIntroduction());
dto.setName(member.getName());
dto.setOrders(orders);
dto.setPhone(member.getPhone());
return dto;
}
}
4. MapStruct
1
2
3
4
@Mapper
public interface MapStructMapper extends MemberMapper {
MapStructMapper MAPPER = Mappers.getMapper(MapStructMapper.class);
}
5. ModelMapper
1
2
3
4
5
6
7
8
9
public class ModelMapperImpl implements MemberMapper {
private final ModelMapper mapper = new ModelMapper();
@Override
public MemberDto map(Member member) {
return mapper.map(member, MemberDto.class);
}
}
벤치마킹
테스트 모델
- 10만건의 Member 객체
- 각 Member에 List«Order» (size: 10)
- 각 Order에 List«Item» (size: 10)
수행 방식
- State » Scope.Thread
- BenchmarkMode » Mode.All
- warmup 10회
- measurement 20회
- fork 3회
성능 비교는 JMH를 이용해 진행했으며 수동 매핑 방식을 기준값으로 두고 비교값은 비율로 표기한다.
결과
| 수동 매핑 | MapStruct | ModelMapper | |
|---|---|---|---|
| Average Time | 1 | 0.99 | 41 |
| Throughput | 1 | 0.97 | 0.02 |
| Single Shot Time | 1 | 1.04 | 28 |
작은 횟수일 때는 큰 차이를 보이지 않았지만 대량의 매핑이 발생할 때 ModelMapper는 매우 느린 결과를 보여준 반면, MapStruct는 직접 매핑 방식과 거의가 차이가 없었다. 같은 매핑 프레임워크면서 왜 이렇게 큰 차이의 결과를 보일까?
내부 구현 비교
ModelMapper
ModelMapper는 런타임에 매핑이 수행되는데 이번 측정에 사용된 다음 코드를 따라가보며 어떻게 매핑되는지 살펴보자.
1
mapper.map(member, MemberDto.class);
ModelMapper는 처음에 원본 객체와 대상 객체의 정보로 context 객체를 만들어 매핑을 진행한다.
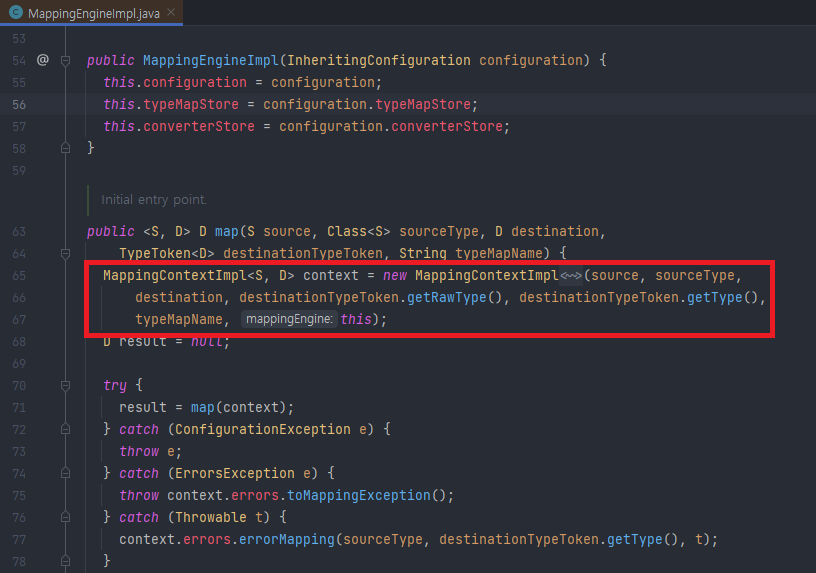
매핑 과정을 쭉 따라가다 보면 원본 객체에서 값을 가져오는 부분이 있는데, 원본 객체의 필드와 1:1로 매칭되는 Accessor 객체의 존재를 확인할 수 있다.
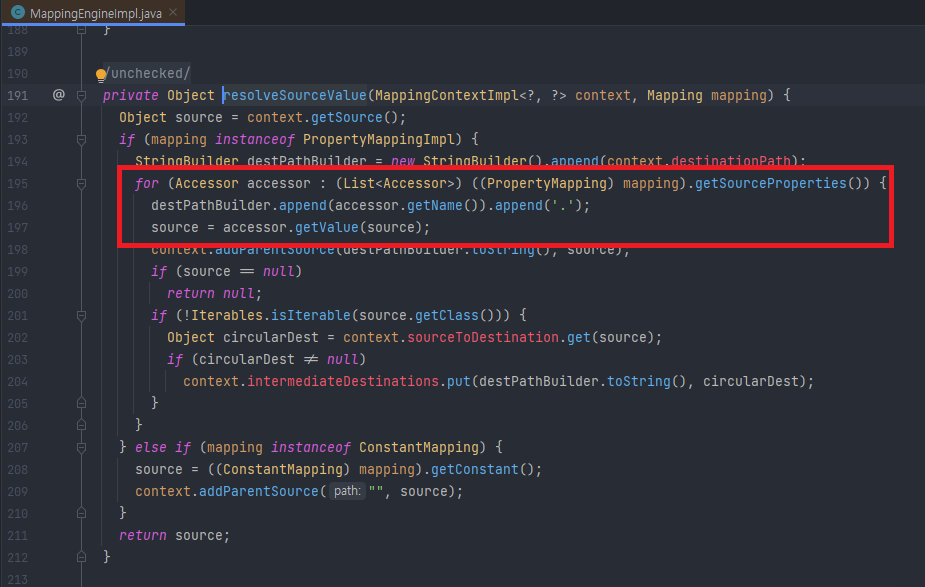
Accessor를 생성하는 부분을 찾아보면 원본 객체가 Map 타입인지, 클래스인지에 따라 Accessor를 만든다.
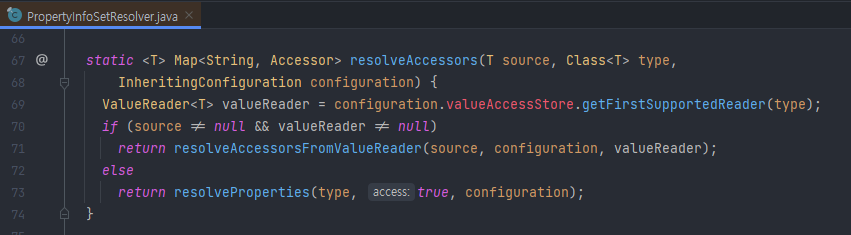
원본 객체가 클래스일 때 생성하는 부분을 보면 표시된 부분에서 프로퍼티 정보를 가진 PropertyInfo 객체를 만드는 것이 보인다. 이 때 구현체는 MethodMutator가 생성된다.
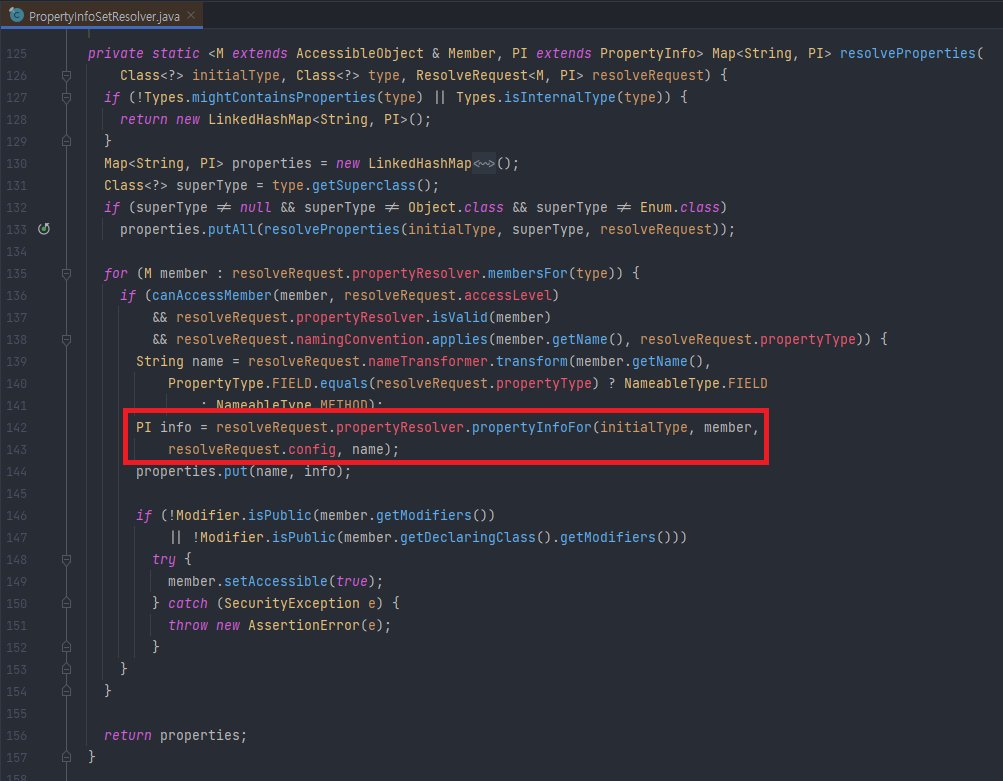
MethodMutator의 내부를 보면 다음 코드가 존재하는데, 원본 객체의 값을 대상 객체의 프로퍼티에 할당할 때, 대상 객체의 set 메서드를 통해 값을 매핑한다.
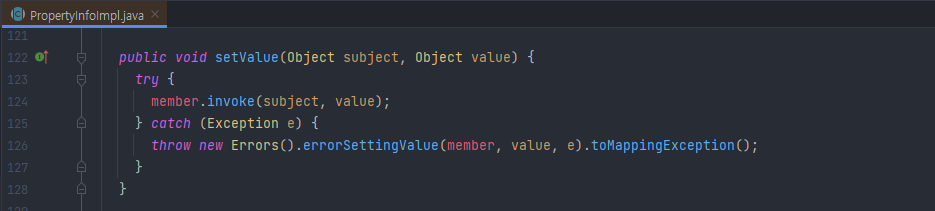
또한, 위 과정과 별개로 값을 실제로 넘겨주는 매핑 코드에서 프로퍼티 개수만큼의 반복문이 한번 더 발생한다.
즉, ModelMapper는 런타임에 리플렉션과 함께 반복이 여러 번 수행되기 때문에 속도가 느린 것이다. 그럼 MapStruct는 어떻게 수동으로 직접 매핑한 방식과 차이가 거의 나지 않는 것일까?
MapStruct
MapStruct는 구현체를 따로 만들지 않았다면 기본적으로 컴파일 시점에 다음과 같은 클래스를 생성해주는데 직접 매핑 코드를 구현한 것과 동일하다. 즉, 런타임 시점에 매핑에 필요한 추가 작업들이 필요하지 않아 직접 구현한 코드만큼 성능이 나오는 것이다.
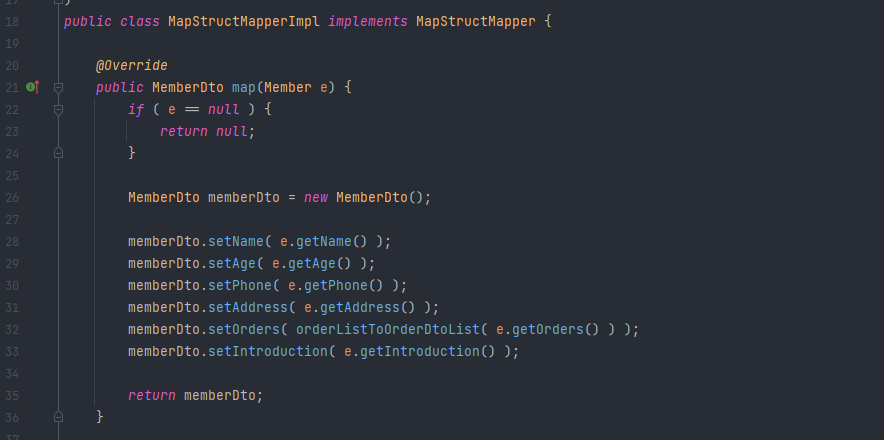
참고
코드는 여기에서 확인할 수 있습니다.